Kartavya
/ Abhi / Sanjeev
cc:
Rajiv / SriRam / Nirmit
Date:
30-11-03
Accuracy
of Extraction
- We
had a long debate on this yesterday with Rajiv, SriRam, and Nirmit.
- Whereas
I agree with them that we have to continuously work on increasing
extraction accuracy, it is a long-drawn-out process. Each incremental
increase in level of accuracy will take more and more effort. Of course,
if we were to design a true Neural Network Software, this
accuracy-improvement process would become totally automatic and require no
human effort. We are far from that stage.
- In
the meantime, we cannot hold up launch/marketing of Recruitguru.
- To
convince potential clients that we have a damn-good product, we must take
help of latest management jargon viz.: SIX SIGMA (a philosophy I
used on Shopfloor of Switchgear Machine Shop, more than 40 years ago!)
- Sanjeev
suggested plotting a graph as shown on enclosed page — (and have it get
automatically updated on the Recruitguru home screen) as proof that our
extraction process not only meets but exceeds what is expected of
it!
|
No.
of Fields that could not be extracted |
No.
of Resumes (processed so far) falling in this category |
|
0 |
10,000 |
|
1 |
20,000 |
|
2 |
40,000 |
|
3 |
40,000 |
|
4 |
10,000 |
|
5 |
6,000 |
|
6 |
2,000 |
|
7 |
800 |
|
8 |
500 |
|
9 |
100 |
|
10–23 |
(remaining
few) |
Kartavya
Date:
22-03-03
Improving
Extraction Accuracy
Abhi
told me last evening that he has planned to process/convert 1,000 email resumes
today morning.
Based
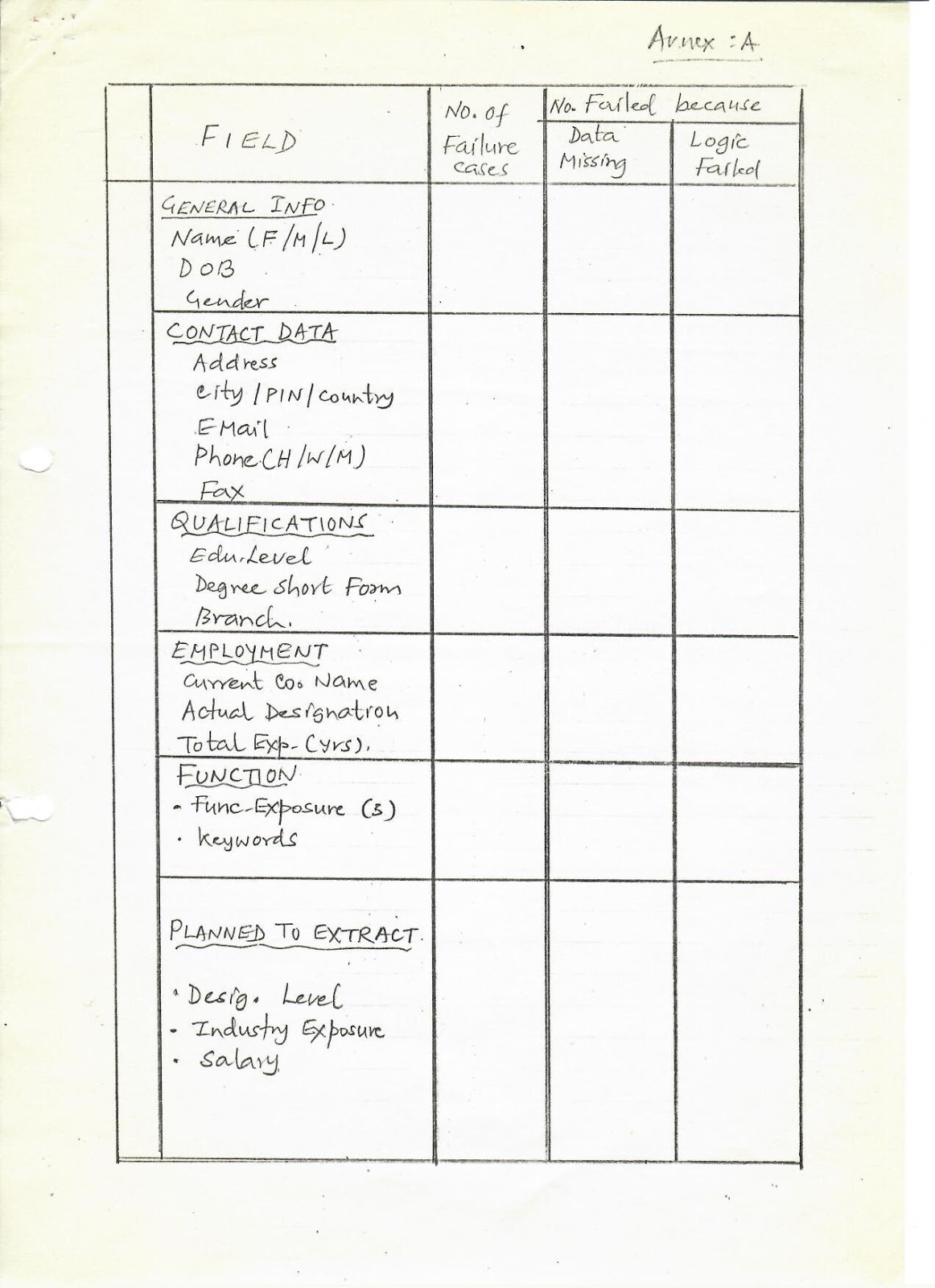
on this “experiment”, remaining 26,000 can be processed next week. When this is
done, a tabulation such as Annex A should be prepared. It can be
rearranged in the descending order of (2nd column) No. of failure cases out
of 27,000.
Descending
order will tell us which cases to tackle first (Priorities).
You
may also consider constructing a TOOL screen, as shown in Annex B.
I
have already modified the existing Resume Screen. Several human experts
could be asked to work on this by examining different “failed” cases — they may
be assigned to different experts.
After studying each failure, these experts should enter their comments into the
middle block.
Of
course, to speed up the process, Vittal / Santu may go through all
“failed cases” in advance and only forward those cases to experts where the
value does exist but the software failed to extract the same.
Then this tool will help us to capture the knowledge of several experts.