BASIS
FOR WORD RECOGNITION SOFTWARE. (24-11-96)
BASIS
FOR A WORD RECOGNITION SOFTWARE.
Any
given word (a cluster of characters) can be classified (in English) into one of
the following "categories":
A
WORD
- Verb
- Adverb
- Preposition
- Adjective
- Noun
So
the first task is to create a directory of each of this category. Then
each word must be compared to the words contained in a given directory. If a
match occurs then that word would get so categorised as belonging to that
category. The process has to be repeated again and again
by
trying to match the word with the words contained in each of the categories TILL
a match is found.
If
no match is found that word should be separately stored in a file marked
"UNMATCHED WORDS".
Everyday,
an expert would study all the words contained in this file and assign each of
these words a definite category, using his "HUMAN INTELLIGENCE".
In
this way, over a period of time, the human intelligence will
identify/categorise each and every word contained in English Language. This
will be the process of transferring human intelligence to computer.
Essentially
the trick lies in getting the computer (software) to MIMIC the process
followed by a human brain while scanning a set of words (i.e. reading) and
by analysing the "sequence" in which these words are arranged,
to assign a MEANING to each word or a string of words (a phrase or a
sentence).
I
cannot believe that no one has attempted this before (especially since it
has so much commercial value). We don't know who has developed this
software and where to find it so we must end-up rediscovering the wheel!
Our
computer files contain some 900,000 words which have repeatedly occurred
in our records - mostly converted biodatas or words captured from bio-datas.
We
have, in our files, some 3500 converted bio-datas. It has taken us about
6 years to accomplish this feat i.e.
- approx.
600 converted biodatas / year
OR
- approx.
2 biodatas converted every working day!
Assuming
that all those (converted) bio-datas which are older than 2 years are OBSOLETE,
this means that perhaps no more than 1200 are current/valid (useful)!
So,
one thing becomes clear.
The
"rate of Obsolescence" is faster than the "rate of
conversion"!
Of
course, we can argue,
"Why
should we waste/spend our time in "converting a bio-data? All we need to
do is to capture the ESSENTIAL/MINIMUM DATA (from each bio-data) which would
qualify that person to get searched/spotted. If he gets short-listed, we can
always, at that point of time, spend time/effort to fully convert his
bio-data."
In
fact this is what we have do so far - because there was a premium on the time
of data-entry operators. That time was best utilised in capturing the
essential/minimum data.
But
if latest technology permits/enables us to convert 200 biodatas each day
(instead of just 2 bio-datas) with the of same effort/time/cost, then
why not convert 200? Why be satisfied with just 2/day?
If
this can be made to
"happen",
we would be in a position to send-out/fax-out/e-mail, converted bio-datas to
our clients in matter of "minutes" instead of "days"
- which it takes today!
That
is not all.
A
converted bio-data has far more KEYWORDS (knowledge - skills - attributes
etc) than the MINIMUM DATA. So there is an improved chance of spotting the RIGHT
MAN, using a QUERY which contains a large no. of KEYWORDS.
So,
to-day if the clients "likes" only ONE converted
bio-data, out of TEN sent to him (a huge waste of everybody's
time/effort), then under the new situation he should be able to "like"
4 out of every 5 converted bio-datas sent to him!
This
would vastly improve the chance of at least ONE executive getting appointed
in each assignment. This should be our goal.
This
goal could be achieved only if,
Step
- #1
- each bio-data received every day is "scanned" on the
same day
- #2
- converted to TEXT (ASCII)
- #3
- PEN given serially (This line appears crossed out or marked to indicate
placement change)
- #4
- WORD-RECOGNISED (a step beyond OCR-optical-character recognition)
- #5
- each word "categorised" and indexed and stored in
appropriate FIELDS of the DATABASE
- #6
- Database "reconstituted" to create "converted"
bio-data as per our standard format.
Steps
# 1/2/3 are not difficult
Step
# 4 is difficult
#
5 is more difficult
#
6 is most difficult
But
if we keep working on this problem, it can be solved.
90%
accurate in 3 months
70%
" in 6 "
20%
" in 12 "
Even
though there are about 900,000 indexed WORDS in our file, all of these
do not occur (in a bio-data/record) with the same frequency. Some occur
far more frequently, some frequently, some regularly, some occasionally and
some rarely.
Then
of course (in the english language) there must be thousands of other words
which have not occurred EVEN ONCE in any of the bio-datas.
Therefore
we won't find them amongst the existing indexed file of 900,000 words.
It
is quite possible that some of these (so far missing words) may occur if this
file (of words) may were to grow to 2 million.
As
this file of words, grows and grows, the probabilities of
- a
word having been left out
- and
such a word likely to occur (in the next bio-data), are decreasing.
The
frequency-distribution curve might look like follows:
Meaning
Some
20% of the words (in english language) make-up, maybe 90% of all the
"occurrences".
This
would become clear when we plot the frequency distribution-curve of the
900,000 words which we have already indexed.
And
even when this population grows to 2 million, the shape (the nature) of
the frequency-
distribution
curve is NOT likely to change! Only with a much large WORD-POPULATION
the "accuracy will marginally increase."
So
our search is to find,
Which
are these 20% ($\approx 20\% \times 9\text{ lakh} = \mathbf{180,000}$)
words which make-up 90% "area under the curve" i.e. POPULATION?1
Then
focus our efforts in "Categorising" these 180,000 words in the
first-place.2
If
we manage to do this, 90% of our battle is won.3
Of
course this pre-supposes that before we can attempt categorization, we must be
able to recognise each of them as a "WOR4D".
COMPANY
SIMILAR
MEANING WORDS
- Firm
- Corporation
- Organisation
- Employer
- Industry
(Misnomer)
ASSOCIATED
WORDS
- Name
of (Company)
- Company
(Profile)
- Present
- Current
- Past
- (Company)
Products
- (Company)
Structure
- (Company)
Organization
Page
11: CAREER
- (Career)
Path
- "
History
- "
Achievement
- "
Growth
- "
Objective
- "
Progression
- "
Information
- "
Details.
- "
Development
- "
Goal.
- "
Interest
- "
Nature.
- "
Profile
- "
Record.
ASSOCIATED
WORDS
- Past
- Present
- Professional
- Academic
- Previous
SIMILAR
MEANING WORDS
CURRICULAM
SIMILAR
MEANING WORDS
RELATED
WORDS
- Academy
- Education
- Exam
- Graduation.
- Honours.
- Institution
- University.
- College
- Degree
- Diploma.
- Certificate
- Learning
- Pass/Passing./Year
of Passing.
- Project
- Training
- Qualifications.
- Scholastic
- Research.
- Scholarship
- Training
- Teaching
EDUCATION
- Education(al)
- Educational
Qualifications
- Qualifications
- Academic
Qualifications
- Technical
"
Associated
Words
- Qualification
- Degree
- Diploma
- Graduate/Graduation
- Post-Graduate
- Doctorate
- Certificate.
- Curriculam
- Course
- Exam
- Topics
- Subjects
- Electives.
- Under-Graduate.
- Fellow
- Honours
- Distinction
- First
class
- Grade
Point Average (CGPA)
- School
- College
- University
- Institution
EXPERIENCE
- Employment
experience
- Work
"
- Job
"
- Professional
"
- Current
"
- Past
"
- Present
"
- Relevant
"
- Industrial/Industry
"
- Teaching
"
- Details
of "
- Foreign
"
- Factory
"
- Global
"
- Management
"
- Site
"
- Major
"
- Practical
"
- Research
"
- Service
"
- Training
"
- Technical
"
EMPLOYER
SIMILAR
MEANING WORDS
- Company
- Firm
- Organisation
- Corporation.
RELATED
WORDS
- Present
- Current
- Past
- Career
- Job
- Service
- Name
of
- Employment
- Employment
Particulars.
- Past
- Present
- Current
- Record
- History
- Existing
- Data
- Nature
- Period.
FUNCTION
SIMILAR
MEANING WORDS
RELATED
WORDS
- Job
- Management
- Description
- Profile
- Skills.
(associated with)
- Structure
(Functional)
- Organisation("
)
- Technical
- Past
- Present
- Existing
- Current
- Con-current
- Major
- Minor
- Nature
of
- Reports
to
FACTORY
WORDS
WITH SIMILAR MEANING.
- Plant
- Site
- Works
- Manufacturing
location.
INFORMATION
WORDS
WITH SIMILAR MEANINGS
- DATA
- KNOWLEDGE
- DATA-BASE
- DATA
SHEET
RELATED
WORDS
- Processing
- Collection
- Retrieval
- Analysis
- Category
- Career
- Details.
- Compilation.
- Particulars.
- Field
of
- General
- Industry
(IT Industry)
- Nature
of
- Purpose
of
- Product/Project
related
- Organisational
- Service.
- state
of
- Dissemination
- Current
- Past
- Personal
- Job
Related
- Work
Related
- Additional
- Institutional.
EXECUTIVE
WORDS
WITH SIMILAR MEANING
- Employee
- Worker/Workman
- Supervisor
- Officer
- Manager
Related
Words
- Data
Sheet.
- Staff
- Workforce
- Performance
- Position
- Search
- Selection
- Placement
- Interview
- Bio
Data
- Resume
- Salary
- Compensation
- Training.
- Experience.
- Function.
- Profile.
- Company.
- Responsibility.
- Status.
- Skills.
- Title
- Designation
- Post.
- Execute
- Exposure
INSTITUTION
Related
Words
- Academic
- Training
- Educational
- Professional.
- Social
- Political
- Economic
- Vocational
- (Institutional)
Membership.
- Technical
- Technological.
- University
- College
- Faculty.
JOB.
WORDS
WITH SIMILAR MEANING
- Service
- Employment
- Work
- Assignment
- Appointment
- Retainership
- Consultancy.
Related
Words
- Function
- Profile
- Nature
- Responsibility
- Estimation
- Evaluation
- Co-ordination
- Description
- Experience
- Exposure
- Knowledge.
- Organisation
- Performance
- Parameters
- Skills.
- Previous
- Past/Present
- Current
- Existing
- Area.
- Category
- Details.
- Duty
- Department
- Division
- Section
- Company
- History
- Major
- Date
of Joining
- Date
of Leaving
- Duration
- Period./Tenure
KNOWLEDGE
Similar
words.
- Skill
- Expertise
- Technique
Related
words
- Job
knowledge
- Working
"
- Computer
"
- Technical
"
- Up-to-date
"
- Client
"
- Product
"
- People
"
- Procedural
"
- Industry
"
- Conceptual
"
- Functional
"
- Market
"
- Practical
"
- Professional
"
- Known
( " ) languages.
NAME
WORDS
HAVING SAME/SIMILAR MEANING
- Personal
Name
- Own
Name
- Surname
- Family
Name
- First
Name
- Middle
Name
- INITIALS
- Full
Name
WORDS
TO BE DISCARDED
- Father's
Name
- Mother's
"
- Wife's
"
- Son/Daughter's
Name
ALSO
USED AS
- Name
of Company
- Employer
- Firm
- Organisation
PRESENT/CURRENT
PAST/PREVIOUS
USED
IN REFERENCE TO
- Job
- Position
- Post
- Designation
- Performance
- Profile
- Work
- Profession.
- Responsibility
- Salary
- Compensation
- Remuneration.
- Service
- Status
- Title
- Experience/Work
Experience.
PROFILE
USED
IN RELATION TO
- Job
- Work
- Current/Present
- Past/Previous
- Customer
- Experience
- Global
- Industry
- Business
- Occupation
- Product
- Professional
- Self
- Service
EXPERIENCE
SIMILAR
MEANING WORDS
USED
IN CONJUNCTION WITH
- Industry
Experience
- Industrial
"
- Teaching
"
- Academic
"
- Analysis
of
- Details
of
- (Production)
Experience
- (Marketing)
"
- (Sales)
"
- (Research)
"
- (Manufacturing)
"
- (Overseas/Foreign)
"
- (Design)
"
- (Management)
"
- (Organisational)
"
- (Product)
"
- (Professional)
"
PHONE
SAME
MEANING WORD
Used
in relation to
- Office
- Residence
- Home
- Factory/Works
- Board
- Direct
- Mobile/Cellular
- Care
of (C/o.)
- Contact
- Directory
ADVERTISEMENT
Used
in relation to
- Job/Job
Opportunity
- Vacancy
- Position/Post
- Recruitment
- Placement
- Institutional
- Product
- Employment
- Criteria
- Media
- Tarriff
- Application
- Bio-data
- Resume
OBJECTIVE
Similar
meaning words
USED
IN RELATION TO
- Career
- Professional
- Developmental
- Management
- Research
- Training.
DATA
Similar
Words
Used
in relation to
- Personal
- Provisional
- BIO
- (Data)
- (Data)
sheet
- (Data)
Capture
- (Data)
base
DATE
Used
in relation to
- Date
of Birth
- "
Joining
- "
Leaving
- "
Graduation
- "
Agreement
- "
Passport
- "
Publication
- "
Qualifying
CONTRIBUTION
SIMILAR
MEANING WORDS
ASSOCIATED
WORDS
- Significant.
- Major
- Past
- Professional
- Technical
BACKGROUND
- Educational
Background
- Professional
"
- Academic
"
- Industry
"
- Social
"
- Experience
"
- Career
"
- Company
"
- Family
"
- Employment
"
- General
"
- Occupational
"
- Personal
"
COMPENSATION
SIMILAR
MEANING WORDS
- SALARY
- REMUNERATION
- PERKS.
- EMOLUMENTS
- PAY
- PAY-SCALE
- REIMBURSEMENT
ASSOCIATED
WORDS
- GROSS
- ANNUAL
- MONTHLY
- CURRENT
- DRAWN
- EXPECTED
- PACKAGE
- CASH
BIO-DATA
SIMILAR
MEANING WORDS
- RESUME
- CURRICULUM
- VITAE
BUSINESS
- Type
of Business
- Business
Volume
- "
Territory.
SIMILAR
MEANING WORDS
POSITION
- Position
Expected
- Position
Held
- Present
Position
- Current
"
SIMILAR
MEANING WORDS
- POST
- DESIGNATION
- TITLE
- PLACEMENT
- STATUS
DESIGNATION
SIMILAR
WORDS
SIMILAR
MEANING WORDS
COMPUTER
- Era
- Education
- Qualification
- Hardware
- Software
- Proficiency
- Skills
- Literacy
- Knowledge
- Languages
- Exposure
ACADEMIC.
- Academics
- Academic
Performance
- "
Qualification
- "
Progress
- "
Credentials
- "
Achievements
- "
Distinction
- "
Institution
SIMILAR
WORDS
- EDUCATION
- EDUCATION
QUALIFICATIONS
- PASS
- PASSING.
ACTIVITY
- Social
- Functional
- Current
- Present
- Past
ASSIGNMENT
- Nature
of Assignment
- Major
- Current
- Business
- Current
- Functional
- Foreign
- Job
- Outstanding
- Present
- Past
- Significant
- Teaching
SIMILAR
WORDS
ACHIEVEMENT
- (Major)
Achievement
- Attainment.
- (Academic)
Achievement
- (Career)
Achievement
- (Outstanding)
Achievement
- (Professional)
Achievement
- (Significant)
Achievement
SIMILAR
WORDS
- HONOURS.
- ATTAINMENT
- PROGRESS
- EXCELLENCE
- HIGHLIGHTS
- MERIT
- DISTINCTION
ACCOMODATION.
SIMILAR
WORDS
ADDRESS
- Office
- Residence
- Home
- Permanent
- Temporary
- Contact
- Current
- Communication
- Correspondence
- Postal
- Posting
- Mailing
- Local.
- Business
- Company..
- Employment
- Factory
- Organisation
- Site
- Works
AGE.
Derivative
- Birth
- Birth-day
- Birth-date
- Born.
- Date
of Birth
AREA.
- Area
of SPECIALIZATION
- Area
of RESPONSIBILITY
- Area
of WORK
- Area
of EXPERTISE
- Area
of EXCELLENCE
- Area
of INTEREST
- Area
of MANAGEMENT
- Area
of TRAINING
1-12-96 ARDIS
= Automatic Resume Deciphering Intelligence Software ARGIS = Automatic
Resume Generating Intelligence Software
What
are these Softwares? What will they do? How will they
help us? How will they help our clients/candidates?
ARDIS
- This
software will break-up/dissect a Resume into its different constituents,
such as:
- a.
Physical information (data) about a Candidate (Executive)
- b.
Academic "
- c.
Employment Record (Industry - Function - Products/Services wise)
- d.
Salary
- e.
Achievements / Contributions
- f.
Attitudes / Attributes / Skills / Knowledge:
- g.
His Preferences w.r.t. Industry / Function / Location
In
fact, if every candidate was to fill-in our EDS, the info. would automatically
fall into "proper" slots/fields since our EDS forces a candidate to
"dissect" himself into various compartments.
But,
getting every applicant/executive to fill-in our standardised EDS is next to
impossible - and may not be even necessary. Executives (who have already spent
a lot of time and energy preparing/typing their bio-datas) are most reluctant
to sit-down once more and spend a lot of time and energy again to furnish us
the SAME information/data in our neatly arranged blocks of EDS. For them, this
duplication is a WASTE OF TIME! EDS is designed for our
(Information-handling / processing / retrieving) Convenience and that is the
way he perceives it! Even if he is vaguely conscious that this (filling in of
EDS) would help him in the long-run, he does not see any immediate benefit from
filling this - hence reluctant to do so. We too have a problem - a "Cost /
Time / Effort"
If
we are receiving 100 bio-datas each day (This Should happen soon), whom to Send
our EDS and whom NOT to?
This
can be decided only by a SENIOR executive/consultant who goes through each
& every bio-data daily and reaches a Conclusion as to
- which
resume's are of Interest & need Sending an EDS
- where
we need not spend time/money/energy of Sending an EDS.
We
may not be able to employ a number of Senior/Competent consultants who can
"Semtise" (all incoming bio-datas and take this decision on a DAILY
basis!). This, itself could be a costly proposition.
So,
on
ONE HAND - we have time/cost/energy/effort of Sending EDS to everyone
on
OTHER HAND - we have time/cost of Several Senior Consultants to Separate out
"chaffe" from "wheat"
NEITHER
IS DESIRABLE.
But
from
each bio-data received daily, we still need to decipher and drop into relevant
slots/fields/ relevant data/information.
OUR
REQUIREMENTS
- match
a candidate's profile with client Requirement Profile
- match
a candidate's profile against hundreds of recruitment advertisements
appearing daily in media (Job BBS.)
- match
a candidate's profile against "specific vacancies" that
any corporation (Client or not) may "post" on our vacancy
bulletin-board (unadvertised vacancies).
- match
a candidate's profile against "Most likely Companies" who
are likely to hire/need such an executive, using our CORPORATE DATA
BASE, which will contain info. such as PRODUCTS / SERVICES of
each & every Company
- Convert
each bio-data received into a RECONSTITUTED BIO-DATA (Converted
bio-data), to enable us to send it out to any client / Non-client
organisation at the click of a mouse.
- generate
(for commercial / profitable exploitation), Such bye-product services as
- Compensation
Trends
- Organisation
charts
- Job
Descriptions
- etc.
etc
- Permit
a candidate to log-into our database and remotely modify/alter his
bio-data.
- Permit
a client (or a non-client) to log into our database and remotely conduct a
SEARCH.
ARDIS
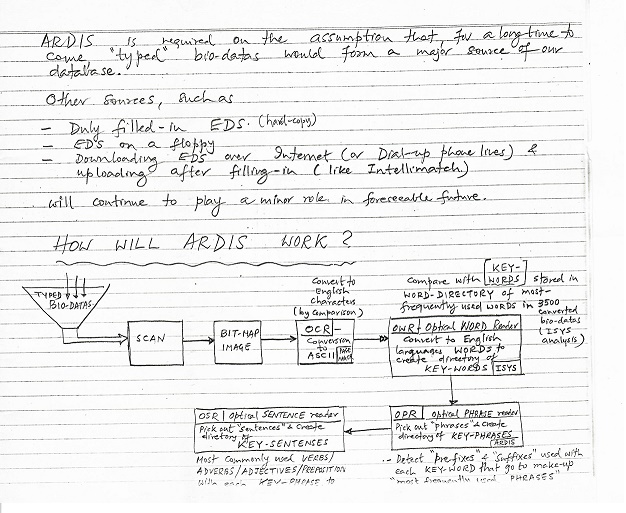
is required on the assumption that for a long time to come "typed"
bio-datas would form a major source of our database.
Other
sources, such as
- duly
filled-in EDS (hard-copy)
- EDS
on a floppy
- downloading
EDS over Internet (or Dial-up phone lines) & uploading after
filling-in (like Intellimatch)
will
continue to play a minor role in foreseeable future.
HOW
WILL ARDIS WORK?
TYPED
BIO-DATAS $\rightarrow$ SCAN $\rightarrow$ BIT-MAP IMAGE $\rightarrow$ OCR
(Conversion to ASCII) $\rightarrow$ KEY-WORD RECOGNISER (Compare with KEY-WORDS
stored in WORD-DIRECTORY of most frequently used words in 3500 converted
bio-datas (2 yrs analysis)) $\rightarrow$ Convert to English characters (by
comparison) $\rightarrow$ Convert to English language WORDS to create directory
of KEY-WORDS (ISYS)
Below
the flow chart are three boxes:
- OSR
Optical Sentence reader
- Pick-out
"sentences" & Create directory of KEY-SENTENCES
- Most
commonly used VERBS / ADVERBS / ADJECTIVES / PREPOSITION with each KEY-PHRASE
- OCR
Optical PHRASE reader
- Pick
out "Phrases" & Create directory of KEY-PHRASES
(ARDIS)
- Detect
"Prefixes" & "Suffixes" used with
each KEY-WORD that go to make-up "most frequently used
PHRASES"
To
recapitulate
ARDIS
will,
- recognise
"characters"
- convert
to "WORDS"
- Compare
with 6258 key-words which we have found in 3500 converted bio-datas (using
ISYS). If a "word" has not already appeared ($>10 \text{
times}$) in these 3500 bio-datas, then its chance (Probability) of
occurring in the next bio-data is very very small. Indeed.1
But
even then,2
ARDIS
Software will store in memory, each "occurrence" of each WORD (old or
new, first time or a thousandth time)3
and4
will
continuously calculate its "probability of occurrence" as5 follows
$$p
= \frac{\text{No. of occurrence of the given Word Sofar}}{\text{Total no. of
occurrence of all the words in the entire population sofar}}$$
So
that,
- by
the time we have SCANNED, 10,000 bio-datas, we would have literally
covered all words that have, even a small PROBABILITY OF OCCURRENCE!
Because
of its SELF-LEARNING / SELF-CORRECTING / SELF-IMPROVING capability,
ARDIS
gets better & better equipped, to detect, in a scanned bio-data
- Spelling
mistakes ( wrong WORD )
- Context
" ( wrong prefix or Suffix ) - wrong PHRASE
- Preposition
" ( WRONG PHRASE )
- Adverb/Verb
" - WRONG SENTENCE.
With
minor variations,
all
thoughts, words (written), Speech (spoken) and actions, keep on repetiting
again and again and again.
It
is this REPETITIVENESS of words, phrases & sentences in Resume's that we
plan to exploit.
In
fact,
by
examining & memorising the several hundred (or thousand)
"sequences" in which the words appear, it should be possible to
"construct" the "grammar" i.e. the logic behind the
sequences. I suppose, this is the manner in which the experts were able to
unravel the "meaning" of hierographic inscriptions on Egyptian...
How
to build directories of "phrases"?
From
6252 words, let us pick any word, say
ACHIEVEMENT
Now
we ask the Software to scan the directory containing 3500 converted bio-datas
with instruction that everytime the word "Achievement" is spotted,
the software will immediately spot/record the prefix. The software will record
all the words that appeared before "Achievement" as also the
"number of times" each of this prefix appeared.
WORD
= ACHIEVEMENT
|
Prefix Word found: | No. of times found (occurrence) | Probability of
occurrence |
|
:--- | :--- | :--- |
|
e.g. | Total no = 55 | = 1.0000 |
|
1. Major | 10 | 10/55 = |
|
2. Minor | 9 | 9/55 = |
|
3. Significant | 8 | 8/55 = |
|
4. Relevant | 7 | 7/55 = |
|
5. True | 6 | |
|
6. Factual | 5 | |
|
7. My | 4 | |
|
8. Typical | 3 | |
|
9. Collective | 2 | |
|
10. Approximate | 1 | |
(Total
no. = 55)
As
more & more bio-datas are scanned,
- The
number of "prefixes" will go on increasing
- The
number of "occurrences" of each prefix will also go on
increasing
- The
overall "population-size" will also go on increasing
- The
"probability of occurrence" of each prefix will go on getting
more & more accurate i.e. more & more representative.
This
process can go on & on & on (as long as we keep on scanning
bio-data's). But "accuracy-improvements" will decline/taper-off, once
a sufficiently large number of prefixes (to the word ACHIEVEMENT, have been
accumulated. Saturation takes place.
The
whole process can be repeated with the words that appear as
"SUFFIXES" to the word ACHIEVEMENT, and the probability of occurrence
of each Suffix also determined.
WORD
= ACHIEVEMENT
|
Suffix | No. of times found | Probability of occurrence |
|
:--- | :--- | :--- |
|
1. Attained | 20 | 20/54 = |
|
2. reached | 15 | 15/54 = |
|
3. planned | 10 | 10/54 = |
|
4. targetted | 5 | |
|
5. arrived | 3 | |
|
6. recorded | 1 | |
54
(Population-size of all the occurrences) 1.000
Having
figured-out the "probabilities of occurrences" of each of the
prefixes and each of the suffixes (to a given word - in this case ACHIEVEMENT),
we could next tackle the issue of "a given combination of prefix &
suffix"
e.g.
what is the probability of
$$\frac{\text{"major"
ACHIEVEMENT "attained"}}{\text{prefix} \quad \text{suffix}}$$
Why
is all of this statistical exercise required?
If
we wish to stop at merely deciphering a resume, then I don't think we need to
go through this.
For
more "deciphering," all we need is to Create a KNOWLEDGE-BASE of
- Skills
- Knowledge
- Attitudes
- Attributes
- Industries
- Companies
- Functions
- Edu.
Qualifications
- Products
/ Services
- Names
- etc
etc.
Having
Created the knowledge-base, simply scan a bio-data, recognise words, compare
with the words contained in the knowledge-base, find CORRESPONDENCE/EQUIVALENCE
and allot/file each scanned word into respective "fields" against
each PEN (Permanent Executive No).
PRESTO!
You
have dissected & Stored the MAN in appropriate boxes.
Our
EDS has these "boxes". Problem is manual data-entry. The D/E
operator,
- Searches
appropriate "word" from appropriate "EDS Box" and
transfers to appropriate Screen.
$$\rightarrow
\quad \text{To eliminate this manual (time-consuming operation) we need
ARDIS.}$$
We
already have a DATA-BASE of 6500 words.
All
we need to do, is to write down against each word, whether
- Knowledge
- Edu.
- Product
- Company
- Location
- Industry
- Function
- etc.
etc.
The
moment we do this what was a mere "data-base" becomes a
"KNOWLEDGE-BASE" ready to serve as a "COMPARATOR".
And
as each new bio-data is scanned, it will throw-up words for which there is no
"clue". Each Such new word will have to be manually
"categorised" and added to the knowledge-base.
Then
what is the advantage of calculating for each word
- each
prefix
- each
suffix
- each
phrase
- each
sentence
its
probability of occurrence?
The
advantages are:
- #1
- Detect "unlikely prefix/suffix"
Suppose
ARDIS detects
"Manor
Achievement"
ARDIS
detects that the probability of
- "Manor"
as prefix to "Achievement" is NIL
- "Minor"
" " " is $0.0009$ (say nil)
hence
the correct prefix has to be
- "Major
(and not "Manor") for which the probability is, say,
$0.4056$.
#2
ARDIS detects
Mr.
HANOVAR
It
recognises this as a Spelling mistake and Corrects automatically to
Mr.
HONAVAR
OR
It
reads.
Place
of Birth: KOLHAPURE
It
recognises it as "KOLHAPUR"
or
Vice-Versa, if it says my name is: KOLHAPUR
#
3
Today,
while scanning (using OCR), when a mistake is detected, it gets highlighted on
the screen or an asterisk/underline starts blinking.
This
draws the attention of the operator who manually corrects the
"mistake" after consulting a dictionary or his own knowledge-base.
Once
ARDIS has calculated the probabilities of lakhs of words and even the
probabilities of their "most likely sequence of occurrences", then,
hopefully the OCR can self-correct any word or phrase without operator
intervention.
So
the Scanning accuracy of OCR should eventually become 100% - and not 75% / 85%
as at present.
#
4
Eventually,
we want that
and
automatically $\downarrow$
- reconstitutes
itself into our Converted BIO DATA FORMAT.
This
is the concept of ARGIS (Automatic resume generating intelligence Software).6
Here
again the idea is to eliminate the manual data-entry of the entire bio-data -
our ultimate goal.7
But
ARGIS is not possible without first installing ARDIS and that too with the
calculation of the "probability of occurrence" as the main feature of
the software.8
By
studying & memorising & calculating the "probabilities of
occurrences" of lakhs of words / phrases / sentences, ARDIS a9ctually
learns english grammar through "frequency of usage".
And
it is this KNOWLEDGE-BASE which enable ARGIS to reconstitute a bio-data (in our
format) in a GRAMMATICALLY CORRECT WAY.
1-12-96.